From unstructured data to SQL queries for searching Customer valuable content
if somehow you get the data of interactions between your customers and your system, say through an agent or chat support, we have ways using AWS managed services to provide us an idea of how many devices are Google or Apple using SQL.
The services to ease our lifes in AWS would be:
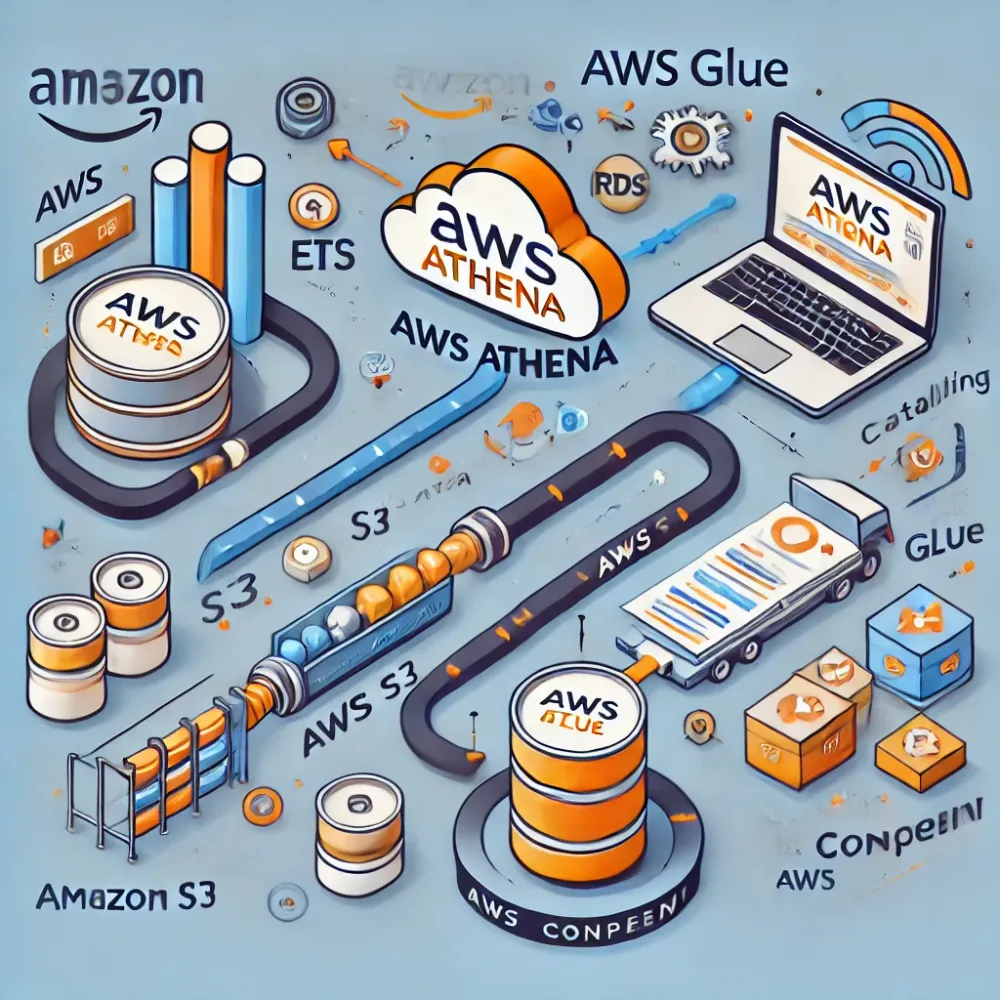
AWS Comprehend (NLP) - to identify entities and categorize them using Analisys Jobs.
AWS Glue - to create a database catalog with a table containing the output from the previous step in the Analisys Jobs using a Crawler, which crawls the data and fills the table and the schema.
AWS Athena - to query using SQL the data catalog filled by the crawler.
1 - AWS Compreehend
Go to Analysis Jobs > Create Job
- specify the Analysis type (Entity recognition, Events, Sentiment, ..)
- S3 bucket for input (example of content)
So tell me how @115911 can tell me in 2014 that "in a year it'll "@115911 needs to ship phones in inconspicuous boxes so they don't @sprintcare @115714 thinking about upgrading my wife's iPhone 6. W "if i would have started a youtube channel years ago Maybe apple wow is too late to pre-order the iphone x through @115911 if I have the "I'm starting to get concerned. There is no label created for my @11 "@115714 went to get the new iPhone 10 today and your sales rep would @TMobileHelp are iPhone X preorders going to come in early ? Mine has @115911 can i use my jumpstart towards getting the iphonex? | @117990 Preordered my #iPhonex on time before 5 on the 27 and still haven't go Preordered my #iPhonex on time before 5csv file
- S3 bucket for output (it will create a tar file) containing the output. The output is a file containing a JSON object per line of the file with Entities telling which entities it found in the line.
{
"Entities": [
{
"BeginOffset": 1,
"EndOffset": 8,
"Score": 0.8560472721418704,
"Text": "@115911",
"Type": "PERSON"
},
{
"BeginOffset": 26,
"EndOffset": 34,
"Score": 0.9982244916180633,
"Text": "iPhone X",
"Type": "COMMERCIAL_ITEM"
},
{
"BeginOffset": 67,
"EndOffset": 71,
"Score": 0.9994100917481371,
"Text": "$200",
"Type": "QUANTITY"
}]
,
"File": "social_media.csv",
"Line": 0
}json
Other lines of the file will contain same structure specific to the line, but with Line 1, Line 2, etc..
2 - AWS Glue
Go to AWS Lake Formation and create a database for Glue.
Go to AWS Glue and create a Crawler against the output file from the tar file (the output file containing what is above in the JSON file containing many entities so that the crawler will identify the schema and create the tables inside our database.
3 - AWS Athena
Athena allows to execute queries against databases, and here is to use the AWS Glue database created previously that should be filled by the crawler.
In athena you can extract a lot of things and gain valuable knowledge and apply SQL queries and groupings and SUMs expressions gaining really valuable insights of contents that aren't relational.
With minimal effort we can start to gain insights of how the business is running.
In a relational database we can execute SQL queries against it and have domain knowledge because things are mostly normalized, but for Unstructured and non-normalized systems, AWS provides a way with minimal effort allowing us to create and gain valuable insights.